Thursday October 28 8:00 AM – Thursday October 28 8:30 AM in Talks I
Best Practices in Machine Learning Observability
Ankit Rathi, Yatin Bhatia
- Prior knowledge:
-
Previous knowledge expected
Machine Learning Basics
Summary
As more and more organizations are turning to machine learning (ML) to optimize their businesses, they soon realize that building ML proof of concepts in the lab is very different from making models that work in production. Things keep changing in production, impacting model perfomance. Lets explore ways to keep ML models effective in production using ML observability and its best practices.
Description
Context and Introduction
We know that Machine Learning is learning from data, where we push the input data and labels, train and expect the model as an output, which we in turn use for predictions.
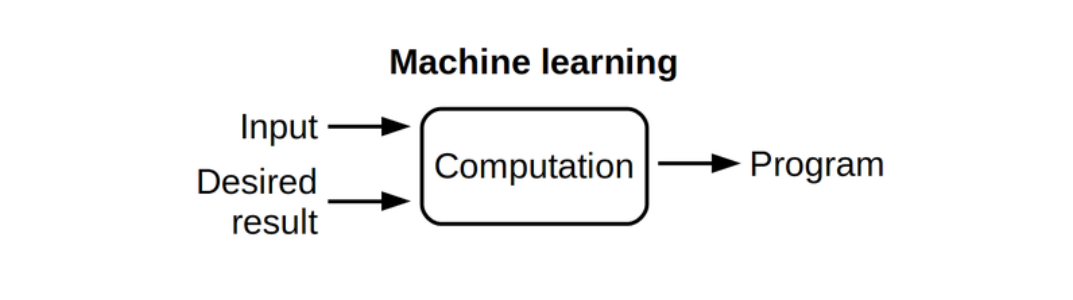
But there is lot more than just building the models that goes into machine learning.
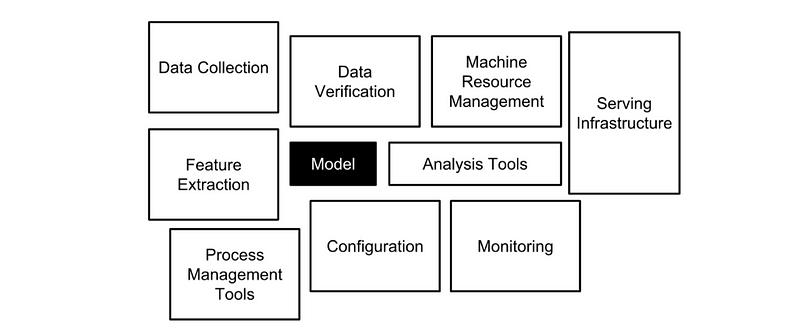
As more and more organizations are turning to machine learning (ML) to optimize their businesses, they soon realize that building ML proof of concepts in the lab is very different from making models that work in production. Things keep changing in production, impacting model perfomance. Lets explore ways to keep ML models effective in production using ML observability and its best practices.
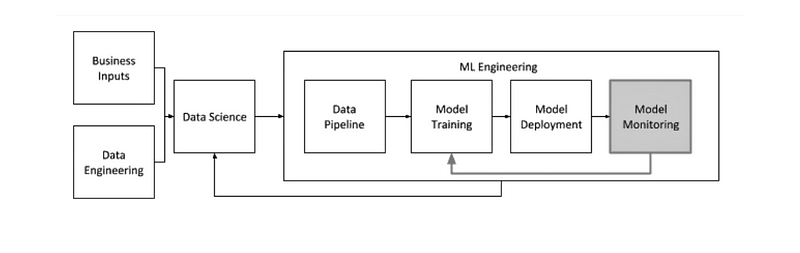
Challenges in ML in Production
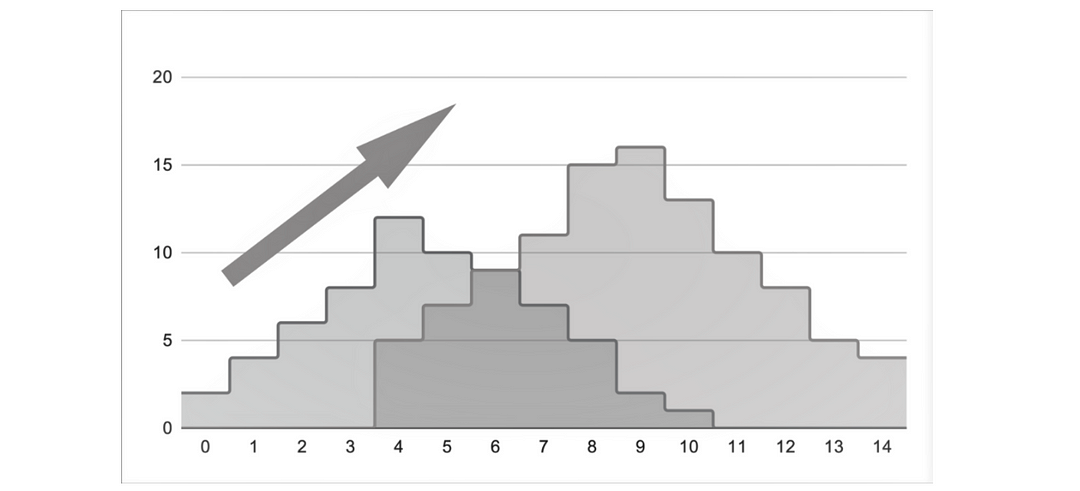
- Data Drift : The first and easiest thing to monitor is what gets fed to the ML, aka the model input. The change in that input is called data drift. A data drift occurs when the distribution of model inputs changes over time, in a significant way. How do we know if a change is significant? A change is significant if it may adversely affect the quality of some models. Data drift may or may not impact business.
- Concept Drift : In most use cases the goal of supervised machine learning is to identify the patterns between model inputs and model outputs. That mapping tends to change over time, and the relationships between applicant data and optimal policy price are not constant. Concept drift almost always impact business.
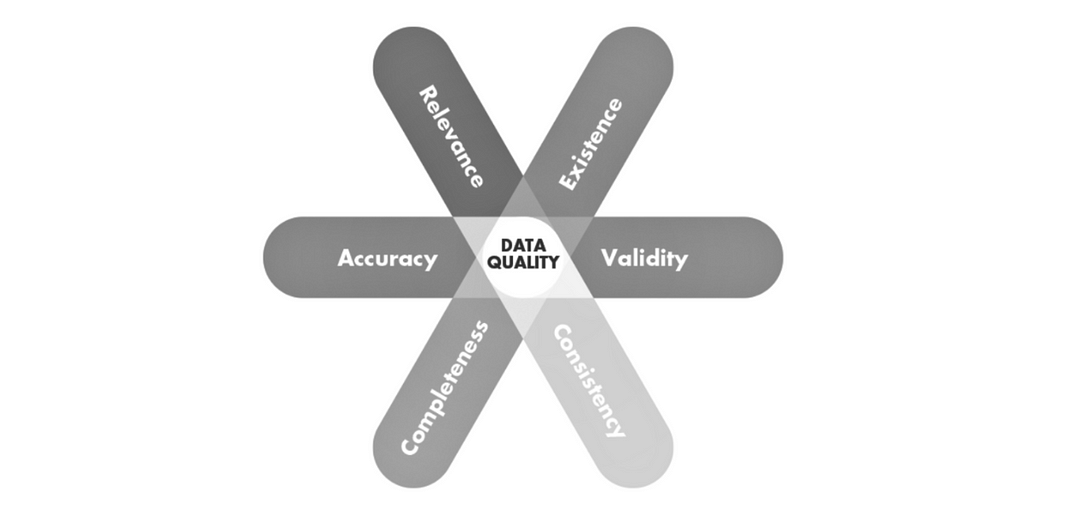
- Data Quality : Another thing to watch out for by is the fidelity of our data sources as data feeds don’t stay constant like code, we are dealing with data.

- Business Impact : Business impact of the ML system is the last thing we have to monitor and it’s relatively a straightforward process if we can compare our predictions with reality.
ML Obervability : Moving beyond Monitoring

ML Observability is all about building a deep understanding into your model’s performance during end-to-end model development cycle i.e. during experimentation, deployment and maintenance in production. ML Observability is not only monitoring the performance, it goes beyond in analyzing performance metrics, analysing the root cause of performance degradation and applying the findings to overcome or mitigating the causes.
How to add Observability to ML pipeline?
-
Monitor Performance : Monitor drift, data quality issues, or anomalous performance degradations using baselines
-
Analyze Metrics : Analyze performance metrics in aggregate (or slice) for any model, in any environment - production, validation and training
-
Conduct Root Cause Analysis : Root cause analysis to connect changes in performance to why they occurred
-
Apply Feedback : Enable feedback loop to actively improve model performance
Best Practices
Cultural Change
- Treat data like a product, so that ownership and accountability is there
- Decentralize knowledge, so that nobody is overwhelmed when the solution scales
- Include observability from experimentation itself, it gets too late once you deploy the model
Monitor your Data
- Process batch and streaming data similarly so that troubleshooting is easier and more intiuitive
- Apart from data drift, focus on feature drift for more insights
- Maintain global data catalog for easier data lineage and data quality tracking
- Measure the baseline of data quality
Monitor your Models
- Anticipate a big dip in performance, automate the detection part
- Maintain twin models (champion model and challenger model) approach
- Version maintain hyperparameters for easier traoubleshooting
Monitor your Predictions
- Watch out for prediction drift but don't relay solely on it (unless ground truth is available)
- Track and deal with unreasonable output from model
Optimize Alerts
- Keep alerts to optimum, not too many, not too less
- Test alerts before moving to production
- Agree on formats and plots/charts
Log Everything that Matters
- Log runtimes, no. of runs, job failures
- Prediction along-side ground-truth
- Data and model versions