This talk will aim to explain the attention mechanism behind some of the very successful models like VQA: Visual Question Answering and Language modelling. Attention is a very successful mathematical tool that helps to overcome some the very crucial problems in sequence-to-sequence model designs.
In this talk, the major focus will be on the newly developed attention mechanism in the encoder-decoder model.
Attention is a very novel mathematical tool that was developed to come over a major shortcoming of encoder-decoder models, MEMORY!
An Encoder-decoder model is a special type of architecture in which any deep neural net is used to encode a raw data into a fixed representation of lower dimension hence it is called ENCODER, this fixed representation is later used by another model, DECODER, to represent the data from encoder model into some other form.
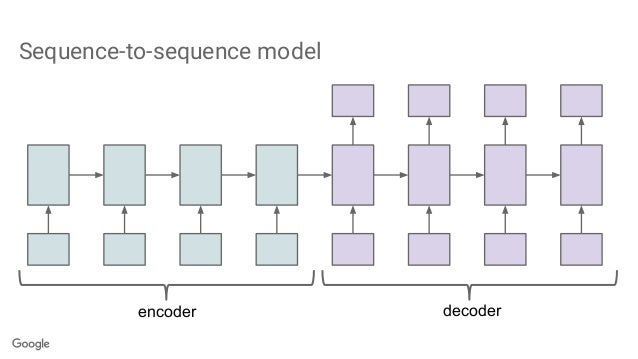 This is a general layout of an encoder-decoder model.
This is a general layout of an encoder-decoder model.
But this model was not able to convert or encode data of very large parameter or sequence the major reason of that is the fixed representation part. This forces the model to overlook some necessary details.
 The bottleneck layer
The bottleneck layer
To solve this problem comes, Attention, a mathematic technique that lets decoder to overcome the problem of fixed representation and thus helps in many tasks further.
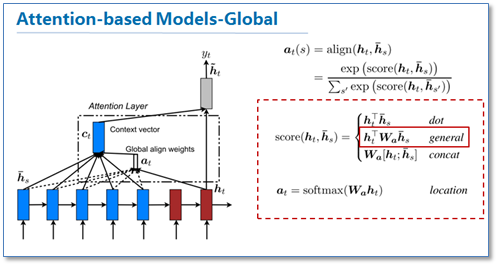
The talk will also focus on the mathematical fundamentals of this mechanism. Brief intro to topics such as early and late attention and soft and hard attention.
A live demo of Visual Question Answer techniques and outro to specific tasks.